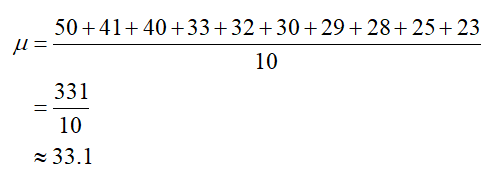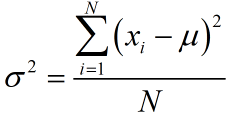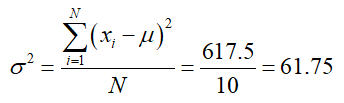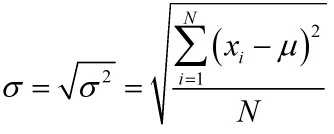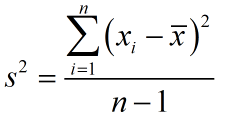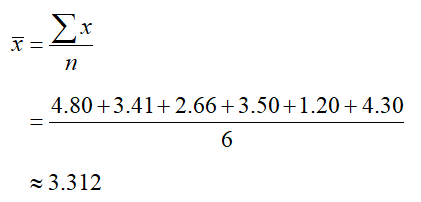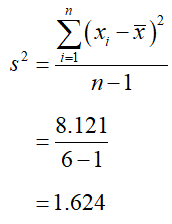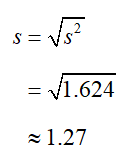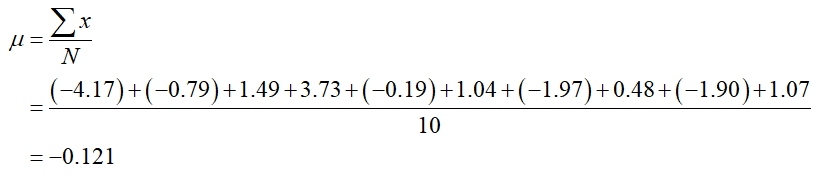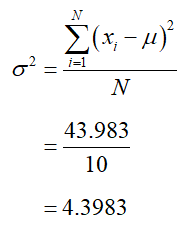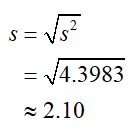The complement of an event E is all of the outcomes in the sample space that are not in the event E. The complement of an event E is represented by the symbols E’. In discussing the complement, we often refer to it as the outcomes not in E. Since the event E and the event not in E combine to give the entire sample space S,
The likelihood of an outcomes in the sample space occurring is certain, so we simplify this to
This leads us to a convenient relationship for determining the likelihood that an outcome in the complement will occur.
Probability of the Complement of an Event
The probability that an outcome in the complement will occur is
In other words, the probability that an event will not occur is 1 minus the probability that it will occur.
Example 3 Probability of the Complement of an Event
In Example 1, we calculated the probability that a smartphone user will use some amount of data in a month. The probability for each outcome and the corresponding probability is listed in the table below
Let E be the event “1GB or more”.
a. Describe the complement of E, E’.
SolutionThe event E contains the one outcome, “2 GB or more”. The complement must contain all of the other outcomes that are in the sample space. We can list those outcomes by writing
This is equivalent to saying that less than 2 GB is used.
b. Find the probability that less than 2 GB of data is used.
SolutionThis event contains four outcomes in the sample space. We could add the probabilities of these outcomes to find likelihood of using less than 2 GB of data. However, it is easier to think of this event as the complement of E and compute
Since the decimal used for P(E) is approximate, so is the value calculated for P(E’) .
In Example 3, it is easier to thin of the event in question as the complement of another event that is simpler to calculate. If the event consists of many outcomes in the sample space, the complement may contain a lot fewer outcomes. This may make it easier to calculate. In the case above, it is easier to use complements than compute
The slight difference between the numbers is due to rounding when the relative frequencies were computed in Example 1.
An event is any collection of outcomes in the sample space. The probability of an event is the sum of the probabilities of the outcomes corresponding to the event.
Probability of an Event
If E is composed of a collection of the outcomes in the sample space S,
then the probability of the event E is
We can use the probabilities of the outcomes in the sample space to find the probability of any event.
Example 1 Probability of an Event
A market research firm conducted a survey of smartphone users to determine their data consumption. The table below indicates the amount of data used in one month.
a. If each row corresponds to an outcome from an experiment, find the probability of each outcome.
SolutionWe will use relative frequencies to estimate the probability of each outcome. Define the outcomes as
The total number of users is 1291 + 758 + 423 + 324 + 947 = 3743. The probability of each outcome is
The sum of decimals are slightly higher than 1. This is due to rounding and is to be expected. However, the sum of the fractions are 1 as they should be.
b. Find the probability that a user will use 1 GB or more of data.
Solution Let A be the event “1 GB or more of data used”. Since A is composed of the outcomes e4 and e5,
c. Find the probability that a user will use 200 MB up to, but not including 2 GB of data.
SolutionLet Bbe the event “200 MB up to, but not including 2 GB of data used”. This event is made up of outcomes e2, e3 and e4. The probability of the event B is
In the previous example, the outcomes from the experiment were estimated using relative frequencies. The probability of events composed of equally likely outcomes may be calculated by counting the number of outcomes in the event. For instance, if an event contains M outcomes(each with probability 1/N), the probability of the event must be
Probability of an Event With Equally Likely OutcomesSuppose the sample space of an experiment contains N equally outcomes. If an event E contains M of those outcomes, the probability of the event is
This expression must be used cautiously since it requires that each outcome in the sample space be equally likely. This expression is often written using the letter n to indicate the number of outcomes in a collection. In this case,
where the notations n(E) and n(S) are the number of outcomes in the event E and sample space S.
Example 2 Probability of an Event
A company supplying bicycle parts ships parts from warehouses located in Newark, New Jersey, Jacksonville, Florida, Industry, California, Portland, Oregon, and Dallas, Texas. Based on past history, the shipping manager has determined that the likelihood of an order being fulfilled by a particular warehouse is the same as being supplied by any other warehouse.
a. Find the probability that an order is fulfilled by the warehouse in Industry, California.
SolutionLet’s consider this to be an experiment where the outcomes are the location where an order is fulfilled. This means the sample space for the experiment is Based on past history, each of these outcomes is just as likely as any other. The event that the order is fulfilled by the Industry warehouse is one outcome of five in the sample space, so
There is a 20% chance that an order will be fulfilled by the Industry warehouse.
b. Find the probability that an order will be fulfilled by a warehouse east of the Mississippi River.
SolutionThis event corresponds to the outcomes Newark and Jacksonville. Since this event contains 2 outcomes from the sample space,
There is a 40% chance that the order will be fulfilled by a warehouse east of the Mississippi River.
There are several ways to assign probability to outcomes in an experiment. The simplest method is to assume that each outcome in the sample space is equally likely. In this case, the probability of each outcome in the sample space is the same as any other outcome in the sample space.
In part c of Example 5, the nanobrewery conducts an experiment to determine what beer is ordered by customers. The sample space for this experiment has three outcomes, brown ale (b), pale ale (p), and lager (l). When the outcomes are equally likely, the probability of each outcome is 1/3. This means a customer is just as likely to order a brown ale as a pale ale or lager.
If the outcomes for an experiment are equally likely, it is easy to determine the probability of each outcome.
Probability of Equally Likely Outcomes
Suppose the outcomes from an experiment are equally likely. If the sample space for the experiment contains n outcomes, then the probabilities of the outcomes are
As long as the number of outcomes in the sample space is finite, we can use this relationship to assign probabilities.
Example 6 Find the Probability of an Outcome
A mining company collects samples from along the Hassayampa River in Central Arizona. They examine the levels of gold present in the sample. The samples are labeled
If the outcomes are assumed to be equally likely, find the probability that there will be no detectable gold in the sample.
SolutionThere are four equally likely outcomes to this experiment. The probability of any outcome is 1/4. Specifically, the probability of no detectable gold present is
Example 7 Find the Probability of an Outcome
In Example 2, we found the sample space for an experiment where a marketing company administers a three question survey where each question is answered yes (Y) or no (N).
If each outcome to this experiment is assumed equally likely, what is the probability that each question is answered no?
SolutionIn Example 2, a tree diagram was used to determine that the sample space for the experiment is
The sample space contains eight outcomes. Since the outcomes are equally likely, the probability of any of these outcomes is 1/8. In particular,
In the example above, we did not attempt correspond the outcome (N, N, N) to an outcome like e1. It was simpler to indicate the outcome by writing the actual outcome instead of the correspondence. Technically, we should indicate that this outcome is part of a collection like the sample space and use braces around it,
Since this complicates the notation, we will typically leave out the braces unless they are needed to clarify the probability being calculated.
Assuming that the outcomes are equally likely is a powerful assumption. It allows us to roll a fair die with six sides and compute the probability of getting a six as 1/6. We can also use this assumption to compute the probability of selecting the king of clubs from a 52 card deck as 1/52. However, this assumption may lead to probabilities that are not realistic.
Suppose a factory worker tests randomly selected items from a production line to determine whether they are defective or not defective. If these two outcomes are assumed to be equally likely,
This factory has a serious problem with quality control! The worker knows from experience that he is much more likely to find that the item is not defective. The equally likely assumption must not be valid.
To get an idea of how likely it is to test an item and find whether it is defective or not defective, the factory worker repeats the testing experiment many times. Out of 500 items, he finds 10 defective products and 490 not defective products. Based on these results, he calculates the probabilities
These numbers are the relative frequencies of each outcome in the sample space. We can estimate probabilities of outcomes by repeating an experiment many times and calculating the relative frequency of each outcome. Probability estimated from relative frequencies in a sample of trials from an experiment is called empirical probability.
Empirical ProbabilityIf an experiment is performed many times, the probability of an outcome to the experiment is
where ei is any outcome in the sample space of the experiment.
Example 8 Find the Probability of Outcomes
A nanobrewery records the type of beers it sells over several days to customers. The frequencies are recorded in the table below.
Use relative frequencies to find the probabilities of each outcome.
SolutionThe total number of beers sold is 90 + 150 + 160 or 400. The probabilities are estimated by dividing each frequency by the total,
Relative frequencies computed from a sample result in probabilities that are estimates of the actual probabilities. If we were to record the number of beers sold over a different set of days or even a few hours, the relative frequencies we would calculate would not be the same as the ones above. If one sample is from a larger proportion of women, we might also expect the relative frequencies to be different.
This may be because the trials are not all comparable. If the nanobrewery carries out the trials during the winter versus during the summer, the brown ale might be more popular. Such beers are typically heartier and traditionally consumed during the winter. Light beers such as a lager are more popular during the summer because of their thirst quench properties. For trials to be comparable, we want to make sure all factors are taken into consideration so that the time of year or day, the gender of the drinker, or other factors do not skew the relative frequencies.
If the number of trials is very small, the probability assessment may be inaccurate. For instance, suppose the nanobrewery calculates the probability of selling lager based on the fact that the last five customers have purchased lagers. According to relative frequencies,
Using this probability, we would assume that there is no possibility of selling pale or brown ale. There is certainly some chance that a pale or brown ale will be sold. Basing the probability on only ten sales leads to a probability assessment that is unreliable.
To ensure the probability assessment is reliable, the number of trials in the experiment must be large and all trails are comparable. When this is done, the relative frequencies for different samples will be approximately the same.
Assuming that outcomes are equally likely or using past history to assign probabilities may not be appropriate. For instance, how likely will it be that the United States economy will suffer a recession next year? Assessing this probability is best done using the experience and judgment. An economist may take all factors into account such as the economies of major trading partners, energy prices, unemployment levels, or debt levels and predict that the likelihood is 10%. Essentially, she is saying there is a 1 in 10 chance of a recession next year. This estimate is based on the knowledge and skill of the economist, not any relative frequencies or logic. A probability assessment like this is a subjective probability assessment. Subjective probability assessments are made when no data exists to calculate relative frequencies or the assumption that outcomes are equally likely is not valid.
Example 9 Find Probability Assessments Subjectively
An economist estimates that the US economy is four times as likely to not suffer a recession as suffer a recession next year. Using this information, find the probability that the US economy will suffer a recession next year.
SolutionThere are two outcomes to this experiment,
Using the information in the problem, the probability of each outcome is written as
Since the sum of the probabilities of the outcomes is 1, we can solve for x,
The probability of each outcomes is
These values match the statement, “the US economy is four times as likely to not suffer a recession as suffer a recession”. The likelihood that the US economy will suffer a recession next year is 0.20. This number might be documented by saying there is a 20% chance that the US economy will suffer a recession next year.
Probability is used to measure the likelihood of something happening. Implicit in the idea of likelihood is chance. We are uncertain what will happen. An experiment is a process that generates uncertain occurrences. These occurrences are called the outcomes of the experiment.
For instance, suppose a manufacturer is producing batteries that are sold in a two pack. If a package of batteries is selected from the production line, the batteries in the package may be examined to determine whether they work or are defective. The process of examining whether the batteries in the package are defective is an experiment. The outcome of the experiment may be listed by indicating whether each battery is working (W) or defective (D).
We can specify the first outcome of the experiment as (W, W). Other outcomes can be written in a similar manner. Written this way, this first letter indicates whether the first battery in the package is working or defective. The second letter indicates whether the second battery in the package is working or defective. We can refer to these outcomes collectively as
The experiment is carried out many times with each outcome being uncertain. These repetitions of the experiment are called trials.
The collection of all possible outcomes of an experiment is called the sample space.
The letter S is used to denote the sample space. The outcomes in the sample space are usually enclosed in brackets.
Example 1 Find the Sample Space
If the battery producer examines the two-pack of batteries and notes the number of defective batteries, find the sample space.
SolutionA two-pack of batteries may have 0, 1, or 2 defective batteries in it. Since the sample space is the set of all possible outcomes,
A tree diagram is useful for listing all of the outcomes from an experiment. For the battery packaging, we draw a pair of line segments from a common starting point to indicate whether the first battery works or does not work.
These line segments form the first branches of the tree. From each of these possibilities, another branch is drawn to indicate what might happen when the second battery in the package is examined.
By examining the tree diagram from left to right, we can list all of the outcomes in the sample space.
A similar strategy can be used for experiments that lead to more complicated branching.
Example 2 Find the Sample Space
A marketing company wishes to survey a group of cell phone customers regarding their phone usage. On the first question of the survey, they will ask whether the customer uses a smartphone. On the second question, they ask whether they are on a family share plan. On a third question in the survey, they ask whether the customer has a texting plan. The answers to the questions are recorded as yes (Y) or no (N). If you consider the administration of the survey to be an experiment, find the sample space of the experiment.
SolutionConstruct a tree diagram like the one shown below.
If we correspond letters to these branches we can write the sample space as
Each outcome corresponds to an ordered triple. This is similar to the ordered pairs we often graph in algebra but with the entries inside the parentheses matching the answer to the questions. Since the survey has three questions on it, we need three sets of branches to specify all possible outcomes and three entries inside of the parentheses.
Often we are interested in a portion of the sample space. An event is any collection of outcomes from an experiment. We represent events with capital letters.
Example 3 Find the Event
The marketing company is interested in several different events. Specify the outcomes that make up each of the events below.
a. The event A, all three questions are answered yes.
SolutionFrom the tree diagram above, we found the sample space
The event A corresponds to the outcome where each entry in the ordered triple is Y,
b. The event B, two of the questions are answered no.
SolutionWe need to find all of the outcomes in the sample space that contain 2 N’s. This event is
c. The event C, the last question is answered yes.
SolutionWe need to find all outcomes where the last question was answered Y. This event is
In each of the parts above, the order in which the outcomes are listed is irrelevant. In other words, we could also write a collection like B as {(N, Y, N), (Y, N, N), (N, N, Y)} or {(Y, N, N), (N, N, Y), (N, Y, N)} . As long as the outcomes are listed inside the brackets, the event is the same. Similarly, the outcomes in the sample space may be listed in any order.
Example 4 Find the Event
Breweries are classified by the amount of beer they produce in a year. The American Brewers Association defines a microbrewery as a brewery that produces less than 15,000 barrels per year. A nanobrewery is a very small brewery where beer is produced in very small batches.
One nanobrewery serves only three beers at a time in its tasting room. The owner conducts an experiment where he keeps track of the first two beers each customer purchases. He uses the letter b to indicate brown ale, p for pale ale, and l for lager, and n for no beer ordered. For instance, bn indicates that the first beer ordered is a brown ale and no second beer was ordered. List the outcomes in each of the events listed below.
a. The event A, only one beer is ordered.
SolutionFor this event, the second letter must be n. If we represent the event with the letter A,
b. The event B, the same beer is ordered for the first and second beer.
SolutionList out all of the outcomes where the letters representing a beer match,
Note that nn is not listed since the event assumes a beer is ordered.
What is the variance and standard deviation of a dataset?
The variance of the data uses all of the data to compute a measure of the spread in the data. The variance may be computed for a sample of data or a population of data. In either case, we must compute how much each data value differs from the mean and square that difference.
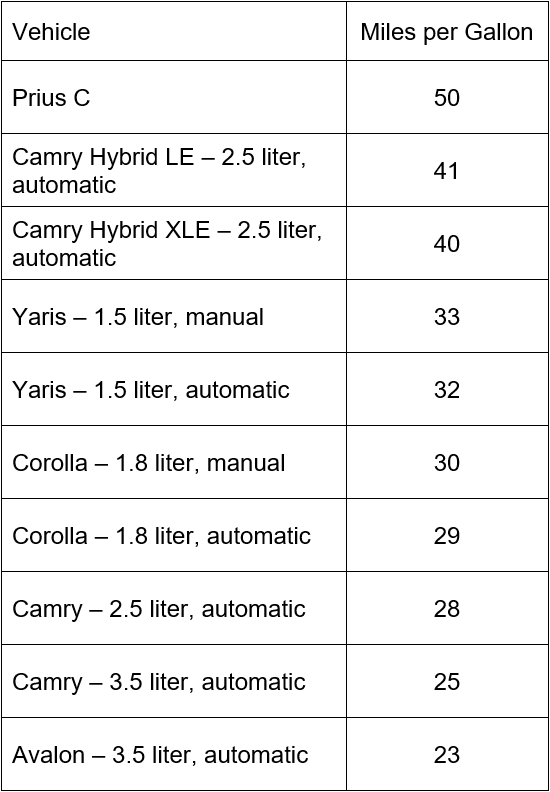
Let’s compute the variance for the mileage of Toyota sedans.
Start by computing the mean of this population,
Next we subtract the mean from each data value and square the result.
The sum at the bottom is found by adding the values in the column. The second column measures how much each data value deviates from the mean. Values higher than the mean give a positive deviation and values lower than the mean give a negative deviation. Since the mean is in the center of the data, the sum of the deviations is zero.
Whether a data value falls above or below the mean should not affect the spread of the data. For this reason, each deviation is squared. The farther the data value is from the mean, the larger the squared deviation is. Values like 23 or 50 have a high squared deviation since they are farther from the mean of 33.1.
Population Variance
The population variance σ2 (sigma squared) of data is the mean of the squared deviations,
where μ is the population mean and N is the population size.
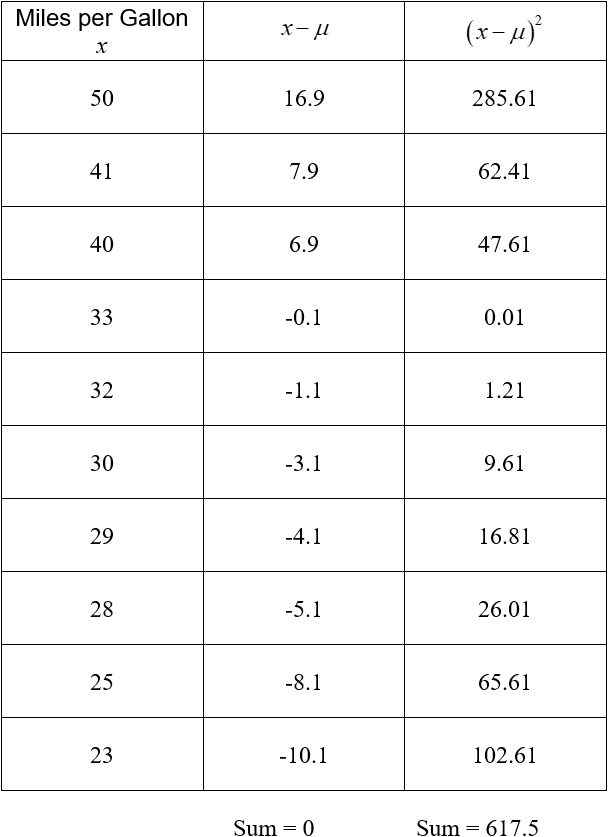
The variance measures the average amount the square of the distance each data value is from the mean. Based on the table above,
The sum in the numerator is the sum of the entries in the third column of the table. On average, each data values squared distance from the mean is 61.75 mpg2 from the mean.
Working in terms of the squared distance is inconvenient. To remedy this, take the square root of the variance. This measure is called the population standard deviation and measures the spread of the data in terms of the units on the data.
Population Standard DeviationThe population standard deviation is the square root of the population variance,
where μ is the population mean and N is the population size.
For the Toyota fleet, the standard deviation is
The larger the variance or standard deviation is, the more spread out the data values are about the mean.
If the data is from a sample instead of a population, the definitions for variance and standard deviation is slightly different.
Sample VarianceThe population variance s2 of data xi is the mean of the squared deviations,
where is the sample mean and n is the sample size.
Sample Standard Deviation
The sample standard deviation s is the square root of the sample variance,
where is the sample mean and n is the sample size.
The main difference between the sample and population standard deviation is the denominator. In the population expressions, the sum of the squared deviations from the mean is divided by the population size N. In the sample expressions, the sum of the squared deviations from the mean is divided by one less than the sample size n. Although the reason for this difference is beyond the scope of this text, using n – 1 instead of n insures that the variance is well behaved. Specifically, if we were to average all sample variances from a population, the resulting average is equal to the population variance.
Despite this difference, the steps for calculating variance and standard deviation for samples or populations is very similar.
Steps for Computing the Variance and Standard Deviation
Identify the data values .
Find the mean of the data values.
Compute the difference between the data and the mean for each data value.
Square each difference between the data and the mean.
Sum the squares of the differences.
If the data is a population, divide the sum by the number of data values N to find the variance. If the data is a sample, divide the sum by one less than the sample size, n – 1.
To find the standard deviation, take the square root of the variance.
Let’s apply these steps to compute the spread in several datasets.
Example 1 Compute the Sample Variance and Sample Standard Deviation
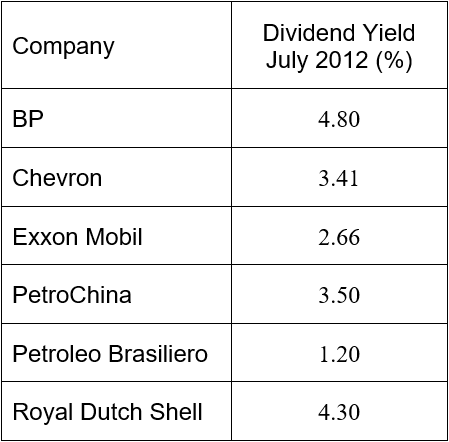
The table below shows the dividend yields of six companies in the New York Stock Exchange energy sector.
a. Find the sample mean.
SolutionThe data in this example are the dividend yields for each company. The sample mean is
The mean has been rounded to three decimal places.
b. Find the sample variance.
SolutionUse a table to compute the differences from the mean and the squared differences from the mean.
Divide the sum at the bottom of the third column by 5 to give the sample variance,
c. Find the sample standard deviation.
SolutionThe sample standard deviation is the square root of the sample variance,
In this example, the original data was written to two decimal places. To insure that we can write the standard deviation to the same number of decimal places, we write numbers in the intermediate steps to one extra decimal place.
Example 2 Compute the Population Variance and Population Standard Deviation
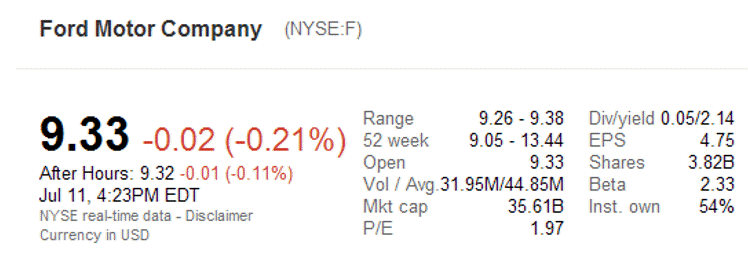
Stock quotes also give the percentage change in a stock from the previous day’s closing price.
For instance, the quote above indicates that Ford closed at $9.33 per share. This was down from $9.31 per share on the previous days close. This is a percentage change of
Percentage changes are often used to determine the volatility of a company’s stock. By computing some statistics on the percentage change, we can get an idea whether a change in the price is normal or not. Consider the percentage changes in Ford’s price per share over ten trading days in June.
a. Find the population mean.
SolutionFor the purpose of this example, we’ll consider the percentage changes over the ten day period to be a population. The mean is
b. Find the population variance.
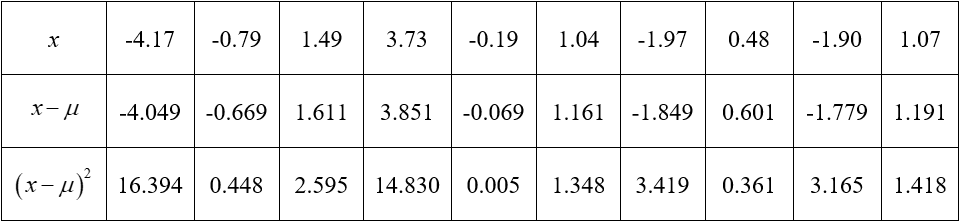
SolutionCalculate the difference from the mean and the squared difference from the mean.
The sum of the bottom row is 43.983. The population variance is
c. Find the population standard deviation.
SolutionThe standard deviation is the square root of the variance,
We’ll see in later chapters that stock traders assume that 68% of stock changes lie within one standard deviation of the mean. A change in price of greater that 2.10% indicates above normal strength or weakness, depending on whether the price rises or falls.