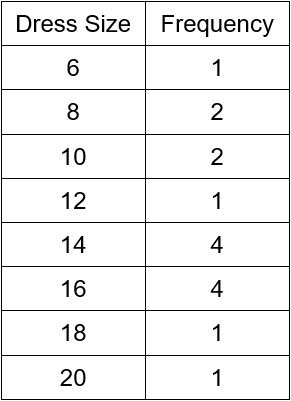
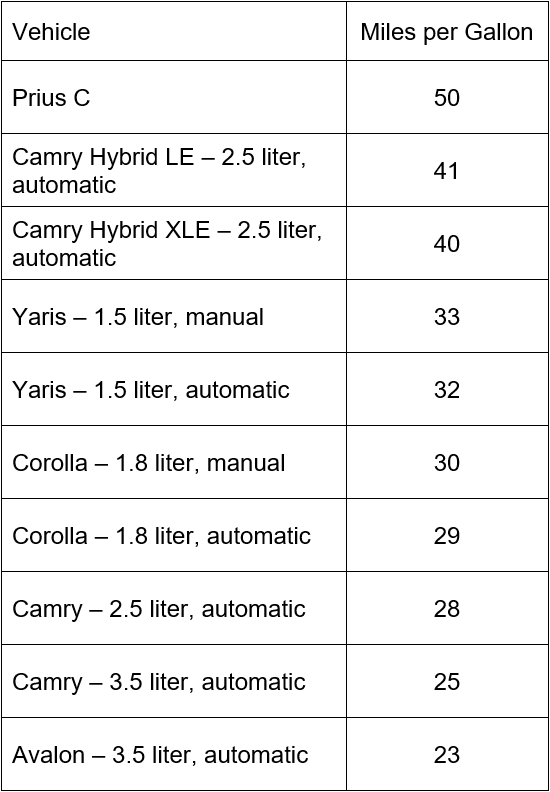
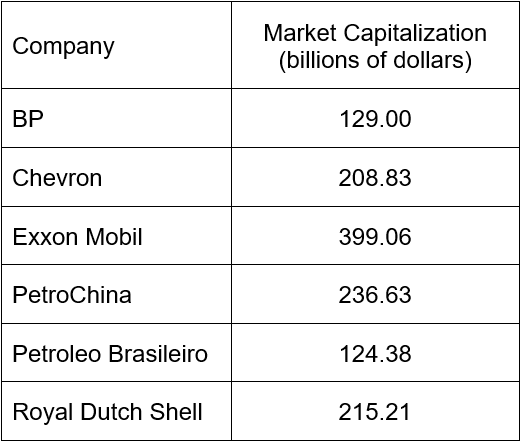
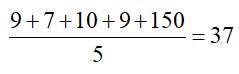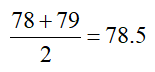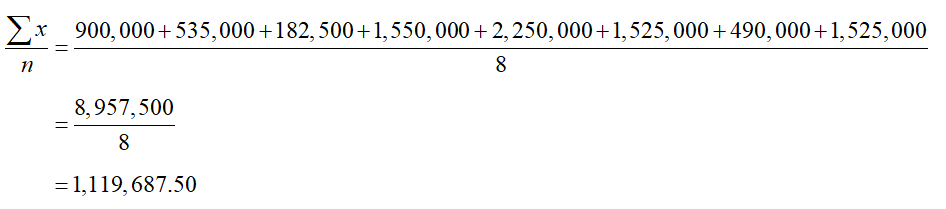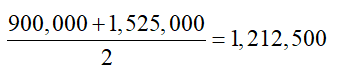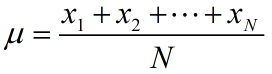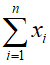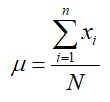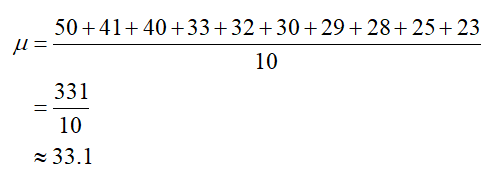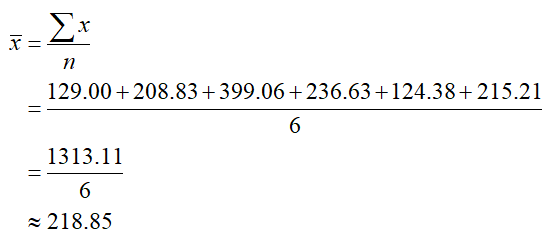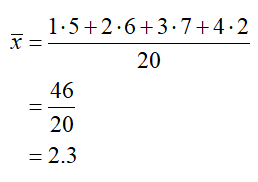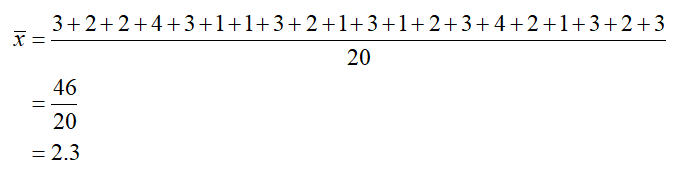What is the range of the dataset?
The simplest way to determine the spread in a dataset is to find the difference between the highest and lowest values in the data. This measure of spread is called the range of the data.
Range
Range = Maximum Data Value – Minimum Data Value
Let’s apply this definition to the closing price of Ford stock over ten trading days in June of 2012.

Based on the closing prices, the stock closed highest on June 6 and lowest on June 4. The range is
Range = 10.57 – 10.04 = 0.53
The range is very easy to compute, but extreme values have a big effect on it. Since the highest and lowest values in the data are the only numbers need to compute the range, large changes in those two numbers will change the range by a large amount. This sensitivity is a weakness of measuring spread with the range.
Stock quotes often include several different ranges. Consider the quote below from Google Finance.
This quote includes two pieces of information that we may use to calculate the range of Pearson’s stock price. The range listed in the middle of the quote is . This is not the same range defined above. Instead, this is the lowest and the highest values of the stock price on July 11. We can use this information to calculate the range of the price for that day,
Intraday Range on July 11 = 19.45 – 19.26 = 0.19
The term “intraday” means within the day.
Next to 52 week we see the values 16.52 – 20.08. These values are the lowest and highest prices for Pearson stock in the previous 52 weeks. The difference between these values is the 52 week range,
52 week Range = 20.08 – 16.52 = 3.56
Each of these ranges is obtained from the stock price as it fluctuates over the day or year.